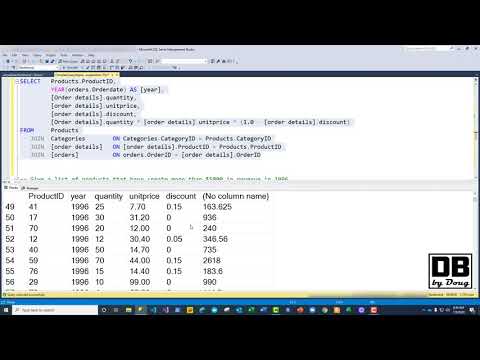
The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause. For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output. Pluck can be used to query single or multiple columns from the underlying table of a model.
It accepts a list of column names as an argument and returns an array of values of the specified columns with the corresponding data type. Expression_n The expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY clause. Aggregate_function It can be a function such as SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. Tables The tables that you wish to retrieve records from. There must be at least one table listed in the FROM clause.

The conditions that must be met for the records to be selected. The ORDER BY clause specifies a column or expression as the sort criterion for the result set. If an ORDER BY clause is not present, the order of the results of a query is not defined. Column aliases from a FROM clause or SELECT list are allowed.
If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. The GROUP BY clause groups a set of rows into a set of summary rows by values of columns or expressions. In other words, it reduces the number of rows in the result set. The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database.

The SQL standard requires that HAVING must reference only columns in the GROUP BYclause or columns used in aggregate functions. However, MySQL supports an extension to this behavior, and permits HAVING to refer to columns in the SELECT list and columns in outer subqueries as well. Corner cases exist where a distinct pivot_columns can end up with the same default column names. For example, an input column might contain both aNULL value and the string literal "NULL". When this happens, multiple pivot columns are created with the same name. To avoid this situation, use aliases for pivot column names.

The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. Because the UNNEST operator returns avalue table, you can alias UNNEST to define a range variable that you can reference elsewhere in the query. If you reference the range variable in the SELECTlist, the query returns a STRUCT containing all of the fields of the originalSTRUCT in the input table. SELECT AS STRUCT can be used in a scalar or array subquery to produce a single STRUCT type grouping multiple values together. Scalar and array subqueries are normally not allowed to return multiple columns, but can return a single column with STRUCT type.

The aggregate functions allow you to perform the calculation of a set of rows and return a single value. The GROUP BY clause is often used with an aggregate function to perform calculations and return a single value for each subgroup. GROUP BY groups a result set by a particular field, and is often used with other aggregate functions like COUNT, SUM, AVG, MIN and MAX. In a query, it is specified in the FROM clause after the table name or subquery.

SQL_BIG_RESULT or SQL_SMALL_RESULT can be used with GROUP BY or DISTINCT to tell the optimizer that the result set has many rows or is small, respectively. For SQL_BIG_RESULT, MySQL directly uses disk-based temporary tables if they are created, and prefers sorting to using a temporary table with a key on the GROUP BY elements. For SQL_SMALL_RESULT, MySQL uses in-memory temporary tables to store the resulting table instead of using sorting. This query contains aliases that are ambiguous in the SELECT list and FROMclause because they share the same name. The INTERSECT operator returns rows that are found in the result sets of both the left and right input queries.

Unlike EXCEPT, the positioning of the input queries does not matter. Set operators combine results from two or more input queries into a single result set. You must specify ALL or DISTINCT; if you specify ALL, then all rows are retained. Query statements scan one or more tables or expressions and return the computed result rows. This topic describes the syntax for SQL queries in BigQuery. A GROUP BY statement in SQL specifies that a SQL SELECT statement partitions result rows into groups, based on their values in one or several columns.
Typically, grouping is used to apply some sort of aggregate function for each group. The GROUP BY statement is often used with aggregate functions (COUNT(),MAX(),MIN(), SUM(),AVG()) to group the result-set by one or more columns. Boolean operators allow you to apply Boolean logic to queries, requiring the presence or absence of specific terms or conditions in fields in order to match documents.

The table below summarizes the Boolean operators supported by the standard query parser. In order to query MongoDB with SQL, Studio 3T supports many SQL-related expressions, functions, and methods to input a query. This tutorial uses the data set Customers to illustrate examples.

The WITH clause, or subquery factoring clause, is part of the SQL-99 standard and was added into the Oracle SQL syntax in Oracle 9.2. The WITH clause may be processed as an inline view or resolved as a temporary table. You should assess the performance implications of the WITH clause on a case-by-case basis. This solution has the same issue when multiple records have the samecreated_at that we discussed earlier, both of those records would find their way into the result. This is because there are no other records to satisfy theON clause for the OUTER JOIN for either of the two records..

I.e. there is no record with a created_at that is greater than their own. You may use the query builder's where method to add "where" clauses to the query. The most basic call to the where method requires three arguments. The second argument is an operator, which can be any of the database's supported operators. The third argument is the value to compare against the column's value.

Union-based SQLi—this technique takes advantage of the UNION SQL operator, which fuses multiple select statements generated by the database to get a single HTTP response. This response may contain data that can be leveraged by the attacker. SQL is a standardized language used to access and manipulate databases to build customizable data views for each user. SQL queries are used to execute commands, such as data retrieval, updates, and record removal.

Different SQL elements implement these tasks, e.g., queries using the SELECT statement to retrieve data, based on user-provided parameters. We use SQL GROUP BY clause to group results by specified column and use aggregate functions such as Avg(), Min(), Max() to calculate required values. STRAIGHT_JOIN does not apply to any table that the optimizer treats as a const or system table.

These tables appear first in the query plan displayed by EXPLAIN. All tables referenced by the query block are locked when OF tbl_name is omitted. Consequently, using a locking clause without OF tbl_name in combination with another locking clause returns an error.

How do you write a group by query in SQL Specifying the same table in multiple locking clauses returns an error. If an alias is specified as the table name in the SELECT statement, a locking clause may only use the alias. If the SELECT statement does not specify an alias explicitly, the locking clause may only specify the actual table name. As a single-set aggregate function, LISTAGG operates on all rows and returns a single output row. The following example selects the range variable Coordinate, which is a reference to rows in table Grid.
Since Grid is not a value table, the result type of Coordinate is a STRUCT that contains all the columns from Grid. A WITH clause contains one or more common table expressions . A CTE acts like a temporary table that you can reference within a single query expression. Each CTE binds the results of a subqueryto a table name, which can be used elsewhere in the same query expression, but rules apply.

The result set always uses the supertypes of input types in corresponding columns, so paired columns must also have either the same data type or a common supertype. The USING clause requires a column list of one or more columns which occur in both input tables. It performs an equality comparison on that column, and the rows meet the join condition if the equality comparison returns TRUE. The GROUP BY clause divides the rows returned from the SELECTstatement into groups. For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. We can use HAVING clause to place conditions to decide which group will be the part of final result-set.

Also we can not use the aggregate functions like SUM(), COUNT() etc. with WHERE clause. So we have to use HAVING clause if we want to use any of these functions in the conditions. Following all rows, an extra summary row appears showing the total inventory of all warehouses and products. In these rows, the values in the warehouseandproductcolumns set to NULL.

Similarly, we can use other aggregate functions such as count to find out total no of orders in a particular city with the SQL PARTITION BY clause. We can add required columns in a select statement with the SQL PARTITION BY clause. Let us add CustomerName and OrderAmount columns and execute the following query. Now, we want to add CustomerName and OrderAmount column as well in the output.
Let's add these columns in the select statement and execute the following code. An aggregate function performs a calculation one or more values and returns a single value. The aggregate function is often used with the GROUP BY clause and HAVING clause of the SELECT statement.

SQL_BUFFER_RESULT forces the result to be put into a temporary table. This helps MySQL free the table locks early and helps in cases where it takes a long time to send the result set to the client. This modifier can be used only for top-level SELECTstatements, not for subqueries or following UNION. A HAVING clause restricts the results of a GROUP BY in a SelectExpression. The HAVING clause is applied to each group of the grouped table, much as a WHERE clause is applied to a select list. If there is no GROUP BY clause, the HAVING clause is applied to the entire result as a single group.

The SELECT clause cannot refer directly to any column that does not have a GROUP BY clause. It can, however, refer to constants, aggregates, and special registers. If you look closely, you'll see that this query is not so complicated. The initial SELECT simply selects every column in the users table, and then inner joins it with the duplicated data table from our initial query. Because we're joining the table to itself, it's necessary to use aliases (here, we're using a and b) to label the two versions.

Generally, it's best practice to put unique constraints on a table to prevent duplicate rows. This tutorial will teach you how to find these duplicate rows. When referencing a range variable on its own without a specified column suffix, the result of a table expression is the row type of the related table. Value tables have explicit row types, so for range variables related to value tables, the result type is the value table's row type. Other tables do not have explicit row types, and for those tables, the range variable type is a dynamically defined STRUCT that includes all of the columns in the table. The UNION operator combines the result sets of two or more input queries by pairing columns from the result set of each query and vertically concatenating them.

The result set always uses the column names from the first input query. In this syntax, you place the GROUP BY clause after the FROM and WHERE clauses. After the GROUP BY keywords, you place is a list of comma-separated columns or expressions to group rows. You can use the GROUP BYclause without applying an aggregate function. The following query gets data from the payment table and groups the result by customer id. Only a few database vendors have the LIMIT clause as known from MySQL, but we support this functionality for all vendors using workarounds.

To use this functionality you have to call the methods setFirstResult($offset)to set the offset and setMaxResults($limit) to set the limit of results returned. We can, however, match the created_at timestamps from most_recent_timestampsto the full row of holding_value_stamps. It's very important that we include all of the fields we used in the GROUP BY as well as the selected created_attimestamp in the ON clause. If we didn't include those fields we may wind up with the wrong data . If the prerequisite is satisfied and the aggregation is always done on a single not-null value, every aggregate function just returns the input value.

However, min and max have the advantage that they also work for character strings (char, varchar, etc.). To obtain the original value for each attribute—even though we have to use an aggregate function—the respective filter logic must not return more than one not-null value. In the example above, it is crucial that each of the named attributes exists only once per submission_id. If duplicates exist, the query returns only one of them. The ROLLUPoption allows you to include extra rows that represent the subtotals, which are commonly referred to as super-aggregate rows, along with the grand total row. By using theROLLUPoption, you can use a single query to generate multiple grouping sets.

In the SQL GROUP BY clause, we can use a column in the select statement if it is used in Group by clause as well. It does not allow any column in the select clause that is not part of GROUP BY clause. In case of mixed data types in a single column, the majority data type determines the data type of the column for query purposes.

The ALL and DISTINCTmodifiers specify whether duplicate rows should be returned. ALL specifies that all matching rows should be returned, including duplicates. DISTINCT specifies removal of duplicate rows from the result set. The UNION operator combines the result sets of two or more SELECT statements by pairing columns from the result set of each SELECT statement and vertically concatenating them. An alias is a temporary name given to a table, column, or expression present in a query. You can introduce explicit aliases in the SELECT list or FROMclause, or BigQuery will infer an implicit alias for some expressions.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.